FPET: Local fitting for national estimation for all women
Leontine Alkema
2026-05-06
Source:vignettes/articles/localnational.Rmd
localnational.RmdIntroduction
In this vignette we obtain national estimates of FP indicators for all women. We use local fits.
Read data for all countries
We use the Track20 survey data base and the UNPD population estimates:
data_folder <- here::here("data-raw")
survey_data_file <- file.path(data_folder, "Track20 2026 Database for FPET2 032726.csv")
nat_population_data_file <- file.path(data_folder, "UNPD 2024 Population through 2050.csv")
# read in data files
survey_df_all <- readr::read_csv(survey_data_file, show_col_types = FALSE)
population_df_all <- readr::read_csv(here::here(nat_population_data_file))Model fitting
First choose a country (division_numeric_code and country names are
available in fpet2::regions_all):
division_numeric_code_select <- 768 # TogoNote that in the current package, the model needs to be compiled
once, this takes a little while. (Note: In the 2024 version, we packaged
up the model using instantiate, we can consider that again
here too).
There will be text indicating what model assumptions are made for married women, followed by assumptions for unmarried women.
results_national <- fit_fpem(
survey_df = survey_df_all |>
dplyr::filter(division_numeric_code == division_numeric_code_select),
population_df = population_df_all |>
dplyr::filter(division_numeric_code == division_numeric_code_select),
service_statistic_df = NULL,
subnational = FALSE,
regions_dat = fpet2::regions_all
)## [1] "This is the FPET2026 version 1.12, released April 17, 2026."
## [1] "When imputing SEs for DHS, we use the effective sample size of its preceding survey"## Joining with `by = join_by(record_id_fixed)`
## Joining with `by = join_by(record_id_fixed)`## [1] "We define possible outliers based on column possible_outlier"
## [1] "We use a global fit, and take selected settings from there."
## [1] "settings for the spline_degree and num_knots taken from global run"
## [1] "Setting for tstar taken from global run"
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models for demand and ds."
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models for demand and ds."
## [1] "Local run, we only use data for TGO"
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models."
## [1] "When imputing SEs for DHS, we use the effective sample size of its preceding survey"## Joining with `by = join_by(record_id_fixed)`
## Joining with `by = join_by(record_id_fixed)`## [1] "We define possible outliers based on column possible_outlier"
## [1] "We use a global fit, and take selected settings from there."
## [1] "settings for the spline_degree and num_knots taken from global run"
## [1] "Setting for tstar taken from global run"
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models for demand and ds."
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models for demand and ds."
## [1] "Local run, we only use data for TGO"
## [1] "We take all hier terms from the global fit, using prefix"
## [1] "For hierarchical terms, we fix things up to the 2nd-lowest level."
## [1] "We fix all sigmas of hierarchical models."## Running MCMC with 4 parallel chains...
##
## Chain 1 Iteration: 1 / 500 [ 0%] (Warmup)
## Chain 2 Iteration: 1 / 500 [ 0%] (Warmup)
## Chain 3 Iteration: 1 / 500 [ 0%] (Warmup)
## Chain 4 Iteration: 1 / 500 [ 0%] (Warmup)
## Chain 4 Iteration: 50 / 500 [ 10%] (Warmup)
## Chain 3 Iteration: 50 / 500 [ 10%] (Warmup)
## Chain 1 Iteration: 50 / 500 [ 10%] (Warmup)
## Chain 2 Iteration: 50 / 500 [ 10%] (Warmup)
## Chain 3 Iteration: 100 / 500 [ 20%] (Warmup)
## Chain 4 Iteration: 100 / 500 [ 20%] (Warmup)
## Chain 1 Iteration: 100 / 500 [ 20%] (Warmup)
## Chain 2 Iteration: 100 / 500 [ 20%] (Warmup)
## Chain 3 Iteration: 150 / 500 [ 30%] (Warmup)
## Chain 3 Iteration: 151 / 500 [ 30%] (Sampling)
## Chain 4 Iteration: 150 / 500 [ 30%] (Warmup)
## Chain 4 Iteration: 151 / 500 [ 30%] (Sampling)
## Chain 1 Iteration: 150 / 500 [ 30%] (Warmup)
## Chain 1 Iteration: 151 / 500 [ 30%] (Sampling)
## Chain 2 Iteration: 150 / 500 [ 30%] (Warmup)
## Chain 2 Iteration: 151 / 500 [ 30%] (Sampling)
## Chain 3 Iteration: 200 / 500 [ 40%] (Sampling)
## Chain 4 Iteration: 200 / 500 [ 40%] (Sampling)
## Chain 1 Iteration: 200 / 500 [ 40%] (Sampling)
## Chain 2 Iteration: 200 / 500 [ 40%] (Sampling)
## Chain 3 Iteration: 250 / 500 [ 50%] (Sampling)
## Chain 4 Iteration: 250 / 500 [ 50%] (Sampling)
## Chain 1 Iteration: 250 / 500 [ 50%] (Sampling)
## Chain 2 Iteration: 250 / 500 [ 50%] (Sampling)
## Chain 3 Iteration: 300 / 500 [ 60%] (Sampling)
## Chain 4 Iteration: 300 / 500 [ 60%] (Sampling)
## Chain 1 Iteration: 300 / 500 [ 60%] (Sampling)
## Chain 2 Iteration: 300 / 500 [ 60%] (Sampling)
## Chain 3 Iteration: 350 / 500 [ 70%] (Sampling)
## Chain 4 Iteration: 350 / 500 [ 70%] (Sampling)
## Chain 1 Iteration: 350 / 500 [ 70%] (Sampling)
## Chain 2 Iteration: 350 / 500 [ 70%] (Sampling)
## Chain 3 Iteration: 400 / 500 [ 80%] (Sampling)
## Chain 4 Iteration: 400 / 500 [ 80%] (Sampling)
## Chain 1 Iteration: 400 / 500 [ 80%] (Sampling)
## Chain 2 Iteration: 400 / 500 [ 80%] (Sampling)
## Chain 3 Iteration: 450 / 500 [ 90%] (Sampling)
## Chain 4 Iteration: 450 / 500 [ 90%] (Sampling)
## Chain 1 Iteration: 450 / 500 [ 90%] (Sampling)
## Chain 2 Iteration: 450 / 500 [ 90%] (Sampling)
## Chain 3 Iteration: 500 / 500 [100%] (Sampling)
## Chain 3 finished in 10.7 seconds.
## Chain 1 Iteration: 500 / 500 [100%] (Sampling)
## Chain 1 finished in 11.1 seconds.
## Chain 4 Iteration: 500 / 500 [100%] (Sampling)
## Chain 4 finished in 11.2 seconds.
## Chain 2 Iteration: 500 / 500 [100%] (Sampling)
## Chain 2 finished in 11.3 seconds.
##
## All 4 chains finished successfully.
## Mean chain execution time: 11.1 seconds.
## Total execution time: 11.4 seconds.
##
## [1] "Chains finished, now calculating estimates (can take a little while)"## Joining with `by = join_by(year, marital_status)`Let’s plot!
plots_all <- plot_estimates_local_all(
results = results_national,
subnational = FALSE,
dat_emu = results_national$dat_emu,
save_plots = FALSE)
print(plots_all)## $TGO
## $TGO$married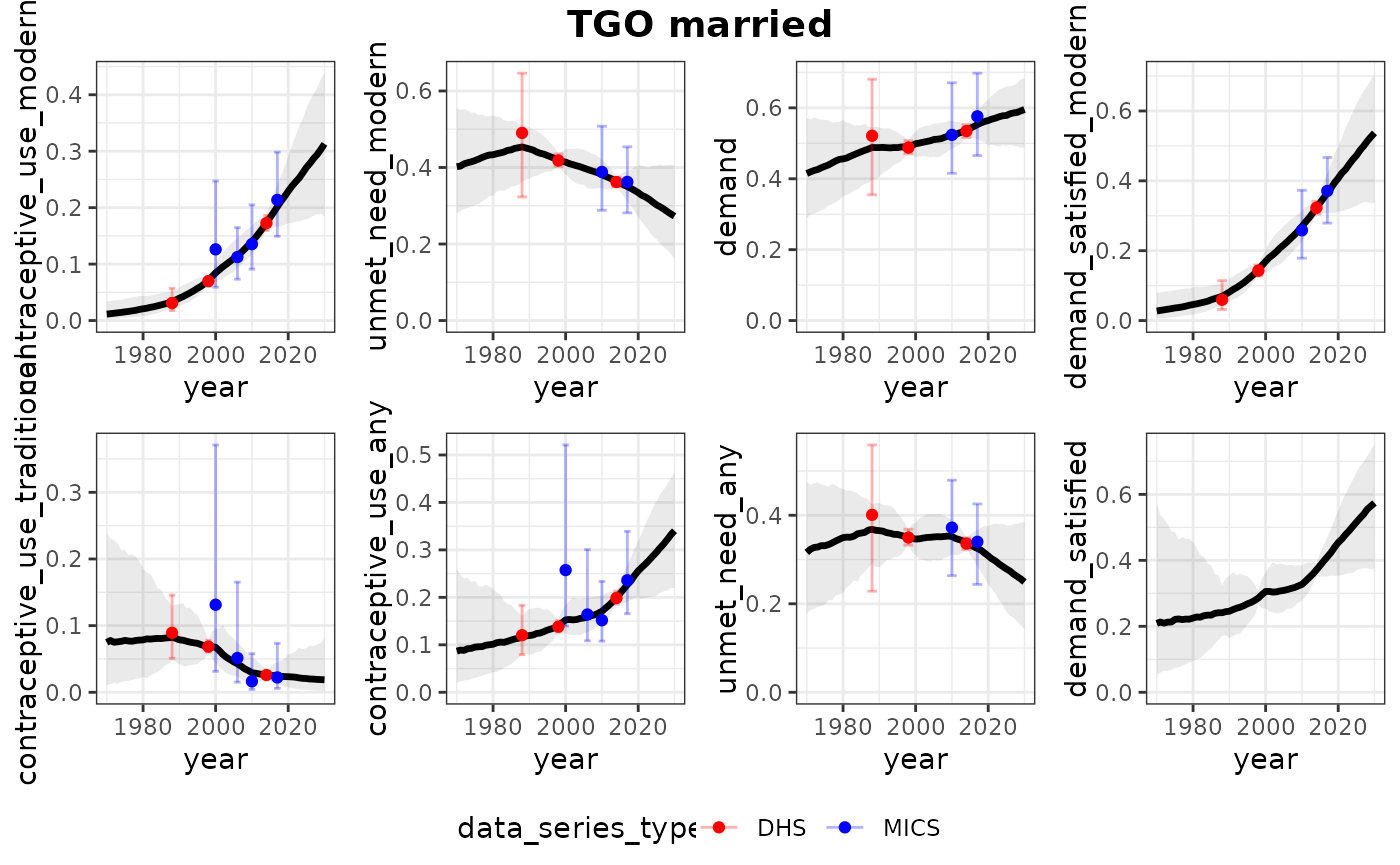
##
## $TGO$unmarried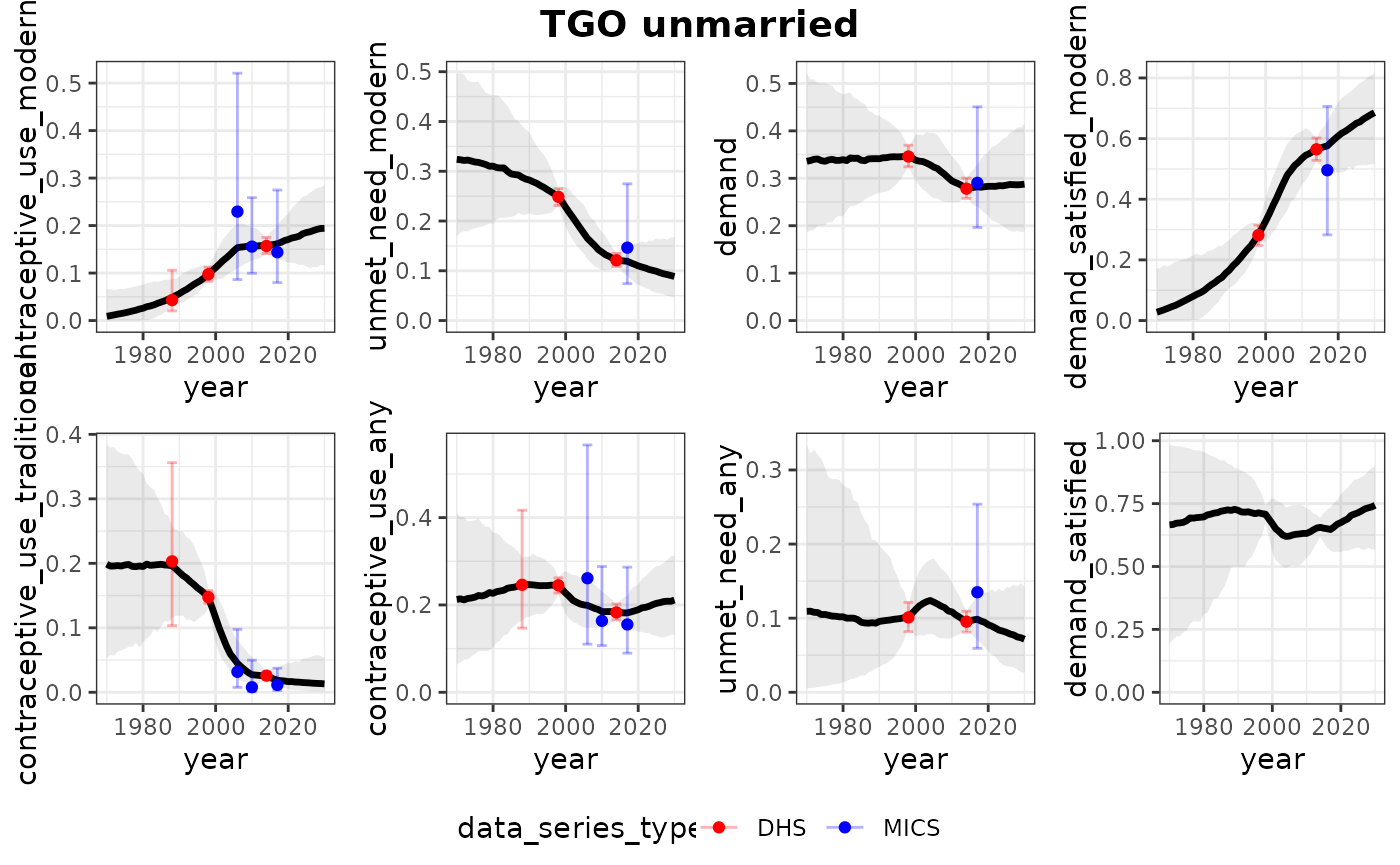
##
## $TGO$all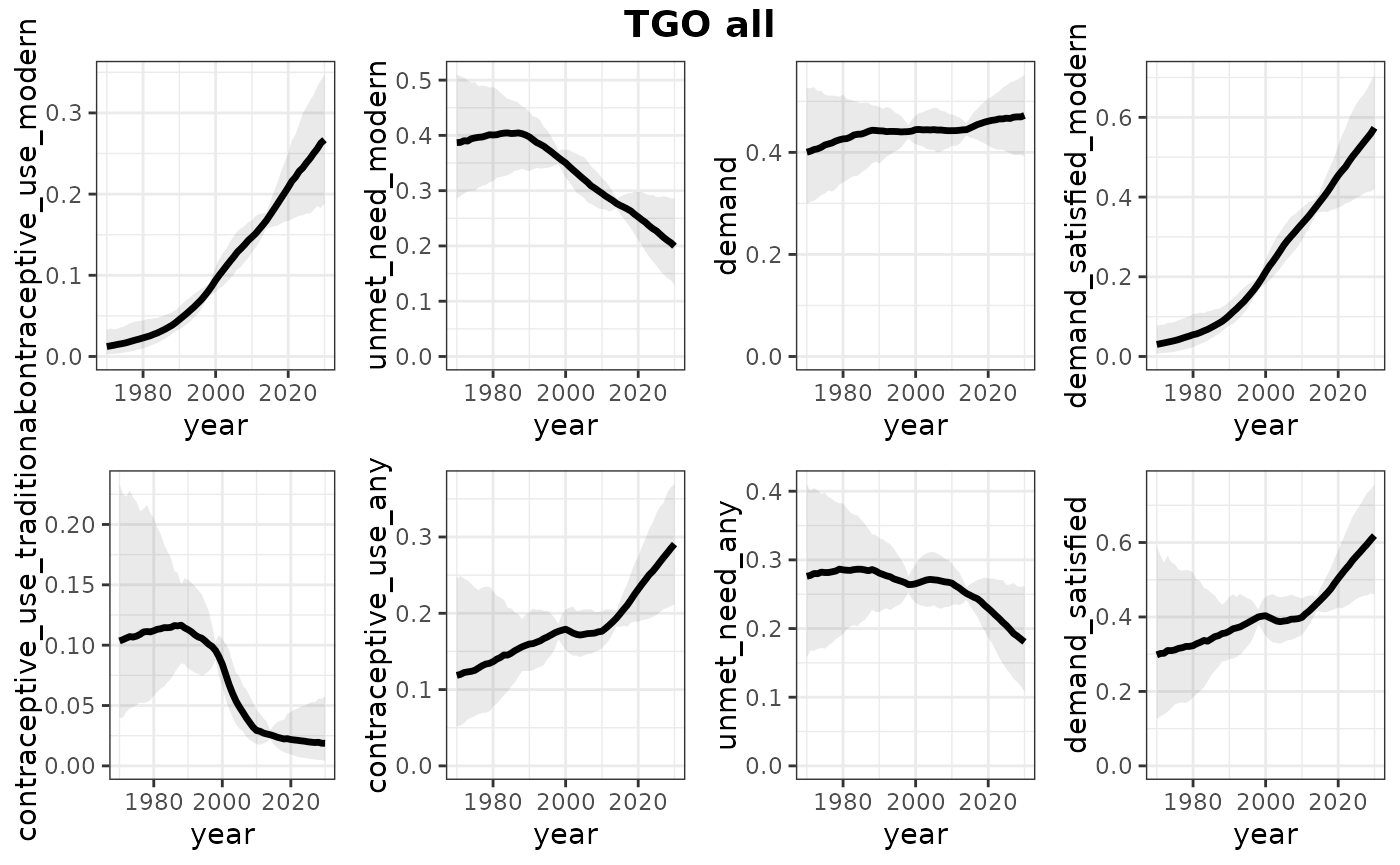
The model fit object also contains the estimates, which can be used for custom plotting or tables. Some examples:
results_national$estimates |>
dplyr::filter(marital_status == "all")## # A tibble: 12,672 × 10
## iso year indicator marital_status percentile division_numeric_code
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 TGO 1970 contraceptive_us… all mean 768
## 2 TGO 1970 contraceptive_us… all mean 768
## 3 TGO 1970 contraceptive_us… all 2.5% 768
## 4 TGO 1970 contraceptive_us… all 2.5% 768
## 5 TGO 1970 contraceptive_us… all 5% 768
## 6 TGO 1970 contraceptive_us… all 5% 768
## 7 TGO 1970 contraceptive_us… all 10% 768
## 8 TGO 1970 contraceptive_us… all 10% 768
## 9 TGO 1970 contraceptive_us… all 50% 768
## 10 TGO 1970 contraceptive_us… all 50% 768
## # ℹ 12,662 more rows
## # ℹ 4 more variables: age_range <chr>, region_code <lgl>, measure <chr>,
## # value <dbl>
results_national$estimates |>
dplyr::filter(measure == "population_count")## # A tibble: 19,008 × 10
## iso year indicator marital_status percentile division_numeric_code
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 TGO 1970 contraceptive_us… married mean 768
## 2 TGO 1970 contraceptive_us… married 2.5% 768
## 3 TGO 1970 contraceptive_us… married 5% 768
## 4 TGO 1970 contraceptive_us… married 10% 768
## 5 TGO 1970 contraceptive_us… married 50% 768
## 6 TGO 1970 contraceptive_us… married 90% 768
## 7 TGO 1970 contraceptive_us… married 95% 768
## 8 TGO 1970 contraceptive_us… married 97.5% 768
## 9 TGO 1970 contraceptive_us… married mean 768
## 10 TGO 1970 contraceptive_us… married 2.5% 768
## # ℹ 18,998 more rows
## # ℹ 4 more variables: age_range <chr>, region_code <lgl>, measure <chr>,
## # value <dbl>